DeepSeek-V3.1-Base
综合介绍
DeepSeek-V3.1-Base是由深度求索(DeepSeek AI)公司开发的一款大型语言模型。它是一个“基础模型”,意味着它是为开发者准备的一个起点,可以被用来进一步训练和调整,以适应特定的应用需求。该模型的一个核心特点是其庞大的规模,拥有约6850亿个参数。 尽管参数总量巨大,但它采用了专家混合(Mixture-of-Experts, MoE)架构,在处理信息时,每次只需要激活其中的一小部分参数(约370亿),这种设计大幅提升了模型的运行效率。 模型支持最长达128,000个字符(token)的上下文处理,能够理解和分析非常长的文档。 该模型以MIT许可证开放源代码,允许开发者免费使用和修改。
功能列表
- 模型架构: 采用专家混合(MoE)架构,总参数量为6850亿,每次推理仅激活约370亿参数,实现了高效的计算资源利用。
- 上下文窗口: 支持长达128K(约128,000个)token的上下文窗口,可以处理和理解长篇文档或复杂的对话。
- 开放源代码: 模型遵循MIT许可证,为商业使用和学术研究提供了极大的自由度。
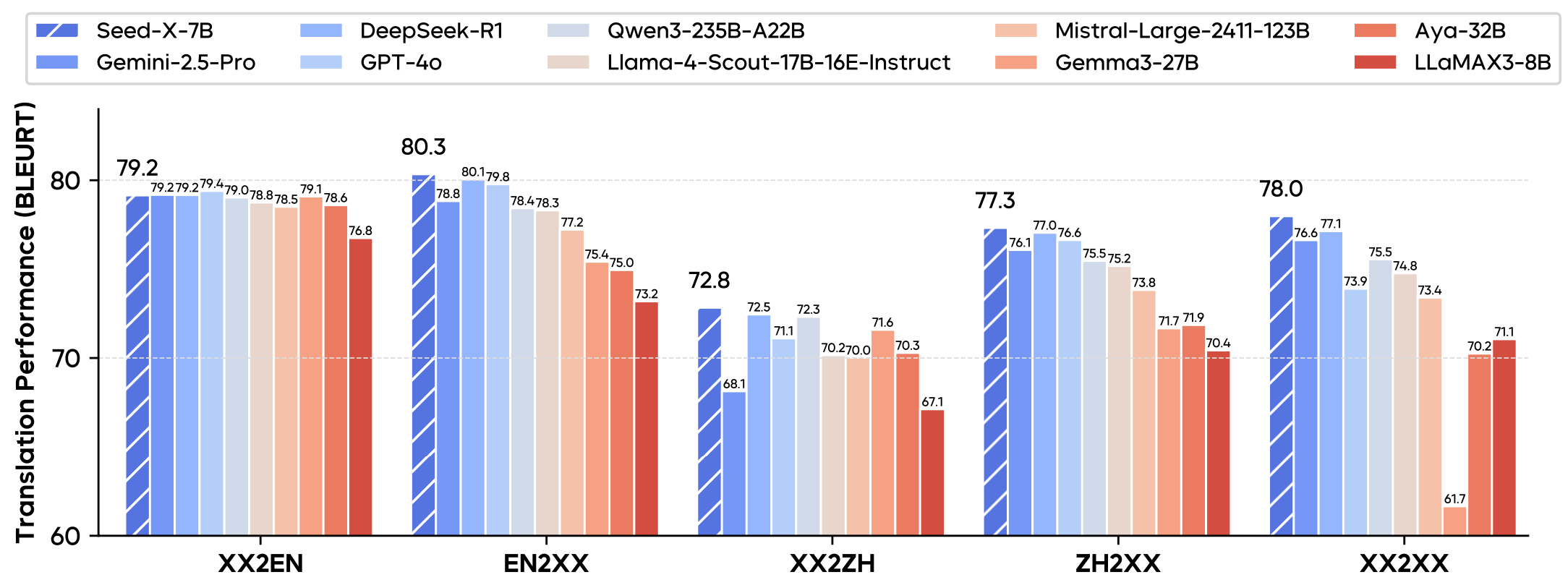
- 多语言能力: 经过优化的多语言支持,能够处理超过140种语言。
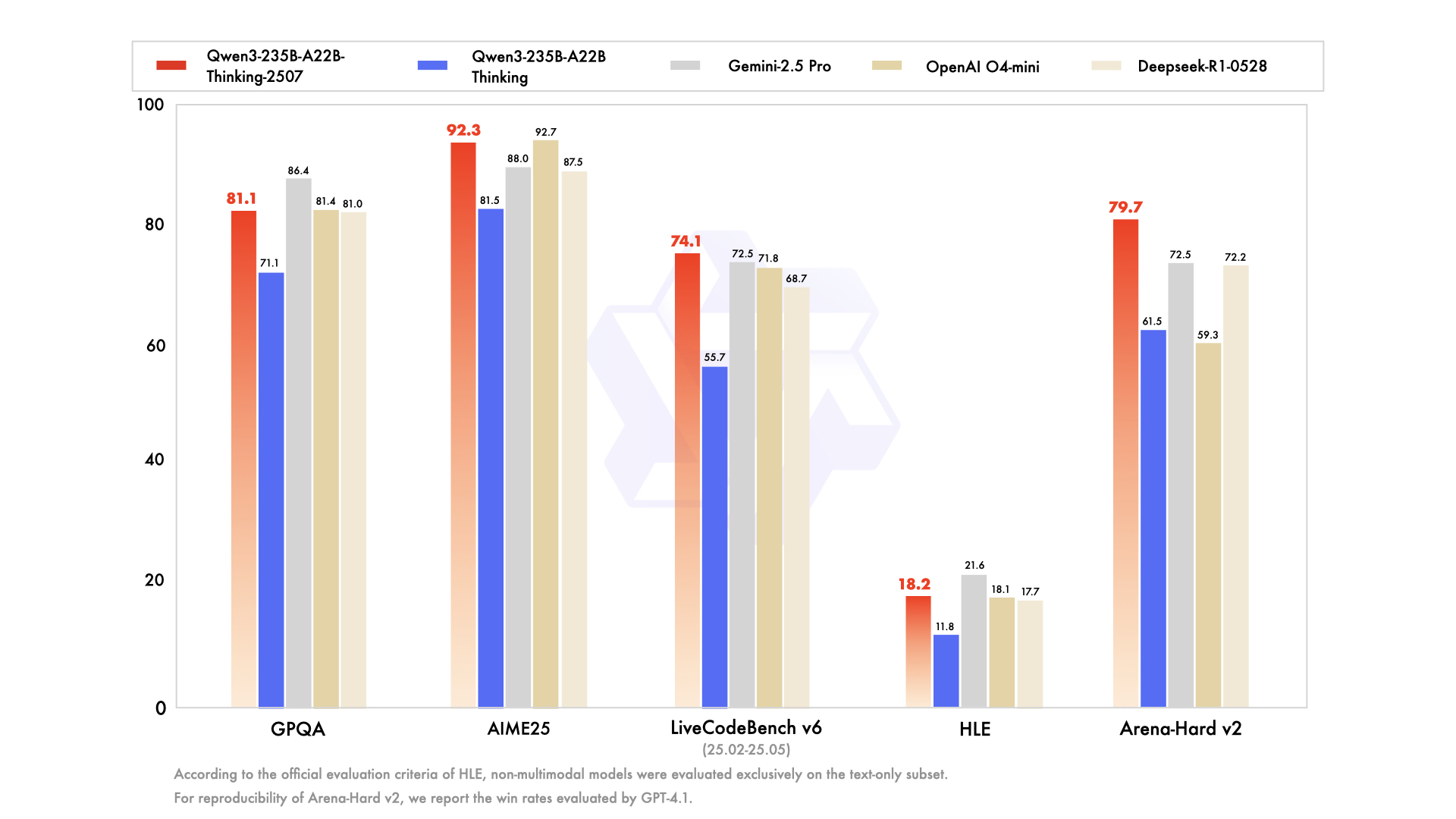
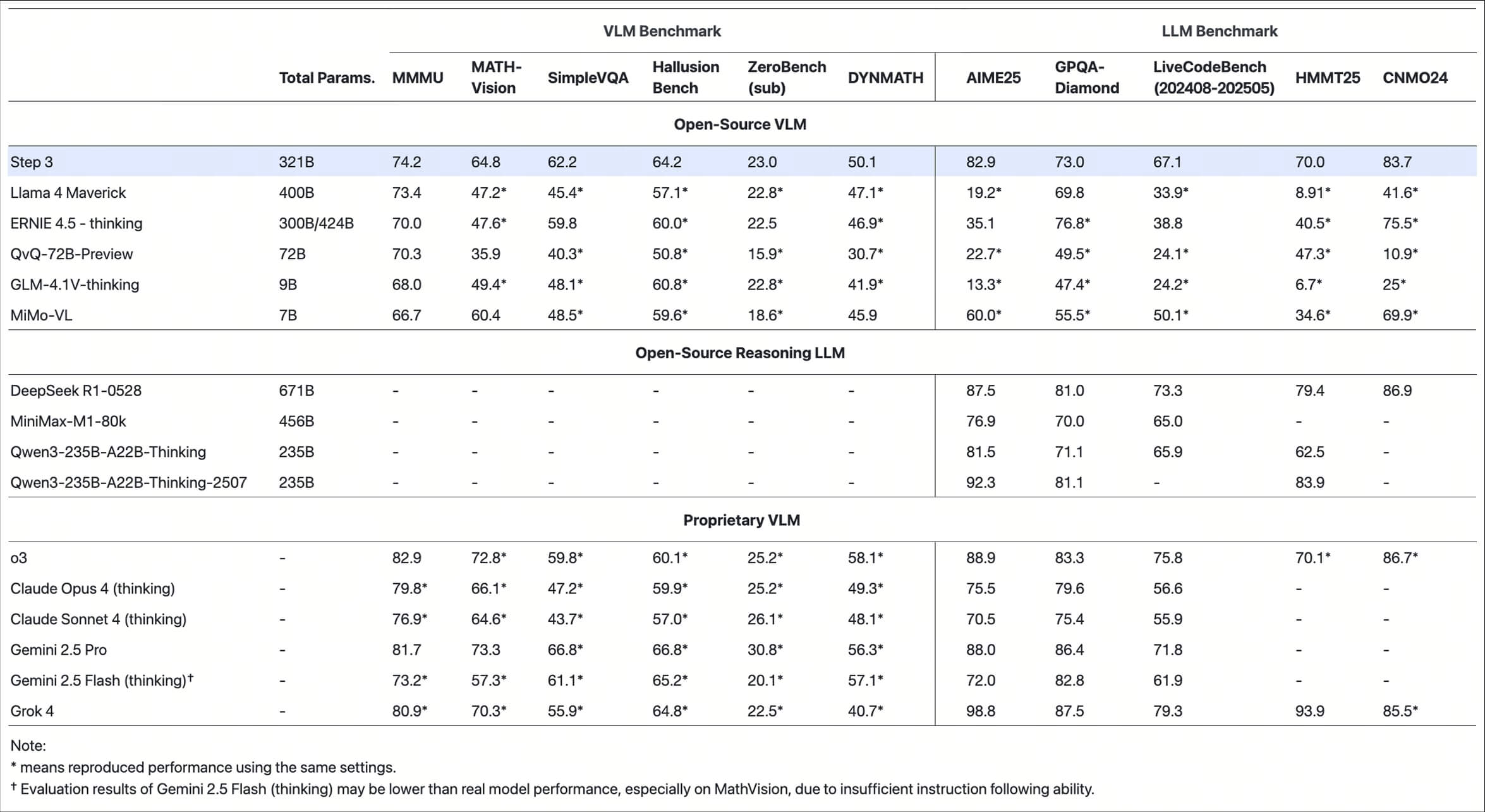
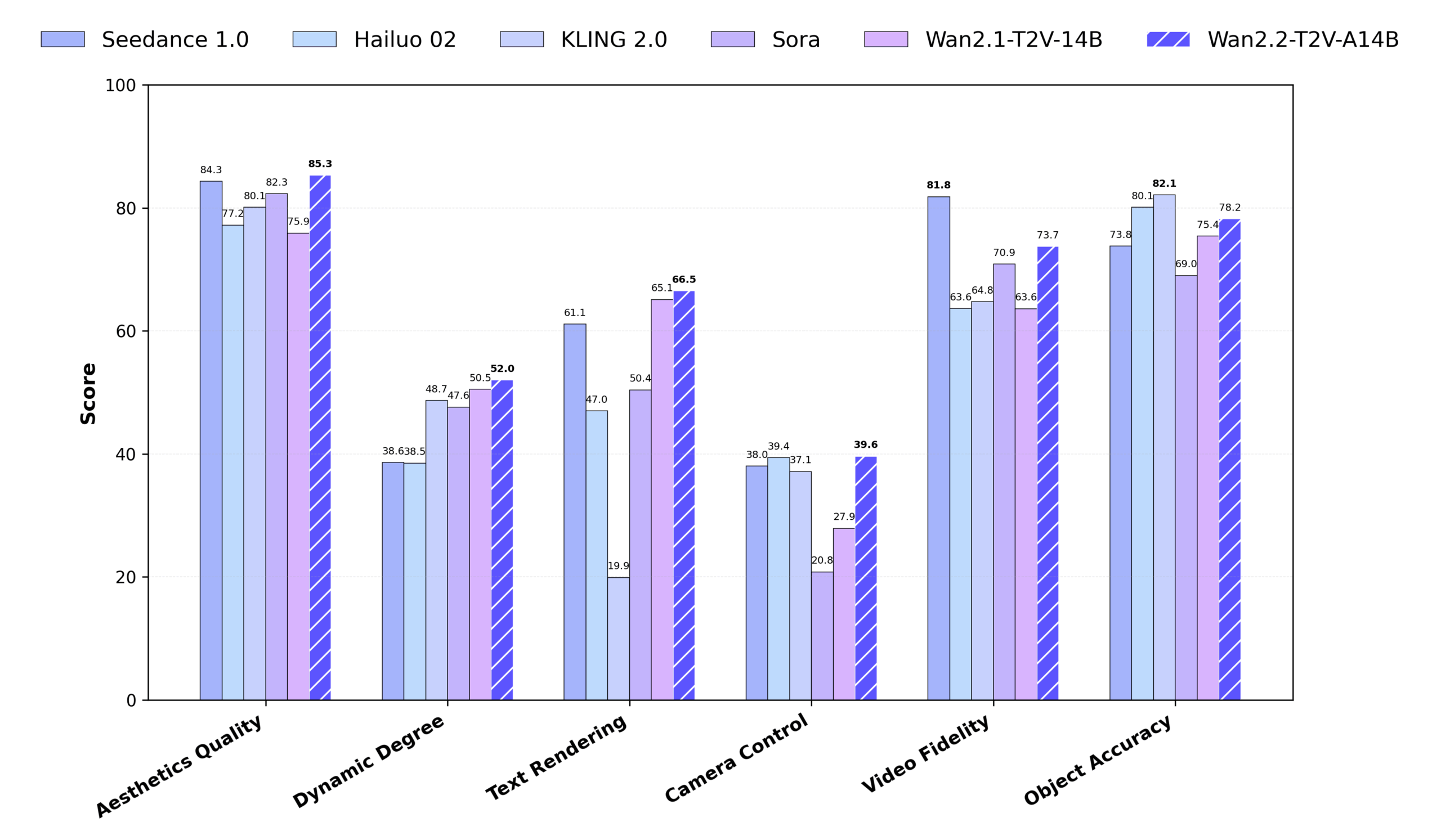
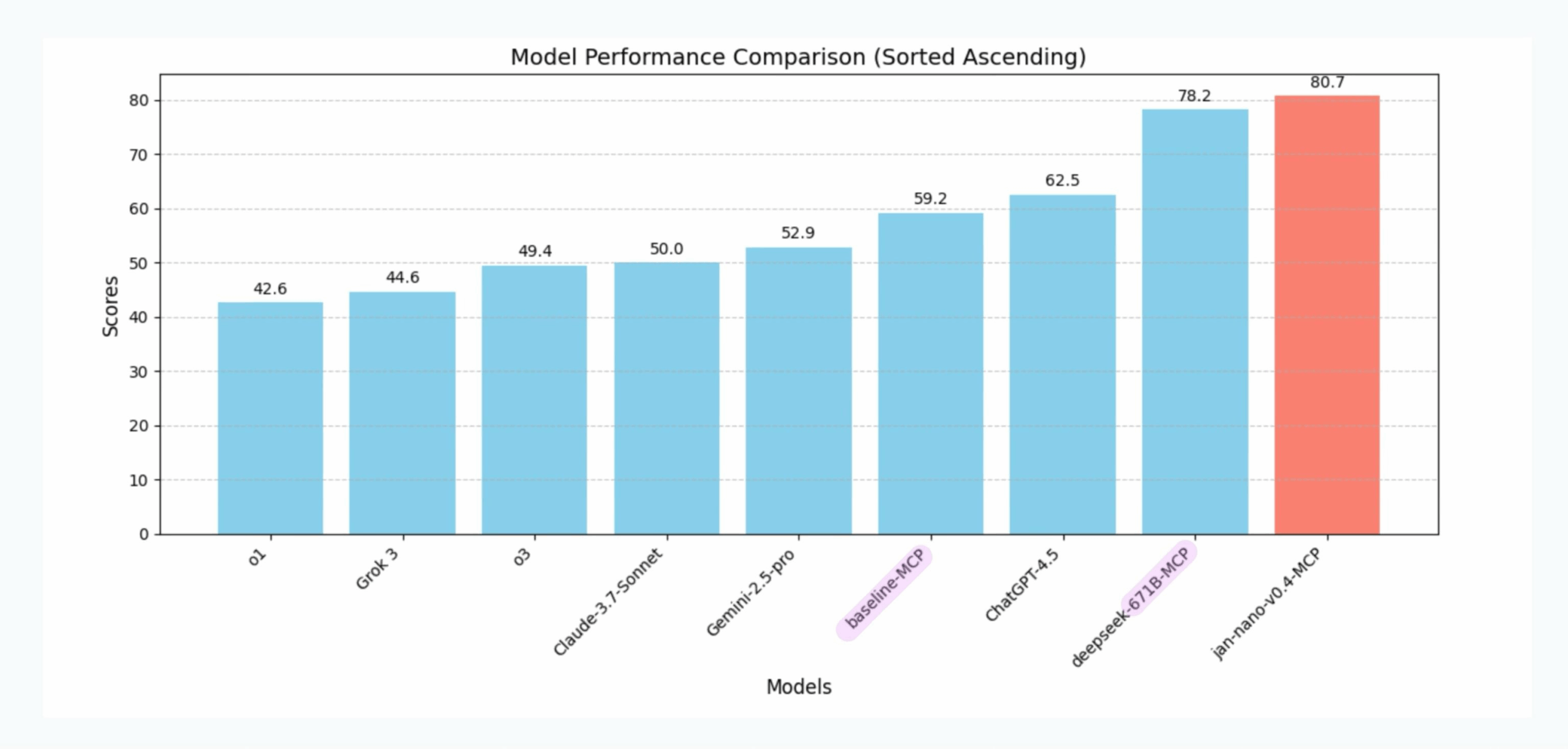
- 强大的性能: 在数学推理、代码生成和通用理解等多个基准测试中,表现出色,性能可与一些行业领先的闭源模型相媲美。
- 高效推理: 采用了多头延迟注意力(Multi-Head Latent Attention, MLA)和FP8混合精度等技术,以优化模型的推理速度和性能。
使用帮助
DeepSeek-V3.1-Base 是一个基础模型,主要面向有开发能力的程序员和研究人员。由于其特殊的架构,它还不能像普通模型那样直接通过Hugging Face的transformers库的默认功能加载,需要一些额外的步骤。
准备工作
在使用模型之前,你需要准备好相应的开发环境。
- 安装Python: 确保你的电脑上安装了Python 3.8或更高版本。
- 安装Git: Git是一个版本控制工具,用于从GitHub下载模型的代码。
- 安装PyTorch: DeepSeek模型依赖PyTorch框架。请根据你的硬件情况(是否有NVIDIA显卡)从PyTorch官网安装。通常使用以下命令:
pip install torch torchvision torchaudio
如何本地运行
要在你自己的计算机上运行DeepSeek-V3.1-Base,由于其巨大的体积和计算要求,你需要一台拥有高端NVIDIA显卡和大量内存的服务器。普通家用电脑无法直接运行此模型。
以下是在具备相应硬件条件下的操作流程:
- 克隆官方代码仓库首先,你需要从GitHub上下载DeepSeek官方提供的运行代码。打开终端(命令行工具),然后输入以下命令:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git这个命令会把名为
DeepSeek-V3的文件夹下载到你的电脑里。 - 进入项目目录并安装依赖下载完成后,进入该文件夹,并安装所有必需的Python库。
cd DeepSeek-V3 pip install -r requirements.txt - 下载模型权重文件模型本身的文件(权重)储存在Hugging Face上。你需要提前下载它们。由于模型文件非常大,请确保你有足够的硬盘空间。你可以从模型的Hugging Face页面手动下载,或者使用git-lfs工具。
- 配置并运行推理服务官方代码库提供多种推理框架的集成,例如
SGLang、vLLM等,这些是专门为高效运行大模型设计的工具。以SGLang为例,你可以使用如下命令启动一个本地的模型服务:# 'path/to/your/model'需要替换成你下载的模型权重文件夹路径 # '--tp 2' 表示使用2个GPU进行张量并行,请根据你的硬件修改 python3 -m sglang.launch_server --model-path path/to/your/model --trust-remote-code --tp 2当服务成功启动后,它会开放一个API端口,你可以像调用OpenAI的API一样,向这个本地服务发送请求,并获取模型的生成结果。
注意事项
- 硬件要求: 运行6850亿参数规模的模型对硬件要求极高,通常需要多张A100或H800级别的专业显卡。
- 自定义代码: 模型在Hugging Face上被标记为
custom_code,这意味着它需要特定的、非标准的源代码来运行。这就是为什么必须克隆官方GitHub仓库的原因。 - 社区支持: 如果遇到问题,可以在Hugging Face模型的社区板块或官方GitHub仓库的Issues页面寻求帮助。
应用场景
- 学术研究研究人员可以利用DeepSeek-V3.1-Base作为一个强大的基础平台,探索大语言模型的工作原理、开发新的算法或进行AI安全等前沿领域的研究。
- 定制化AI应用开发开发者可以在这个基础模型之上进行微调(fine-tuning),训练出针对特定行业的专属模型,例如医疗领域的问诊助手、金融领域的市场分析工具、或法律领域的合同审查系统。
- 内容创作和生成企业或个人开发者可以利用该模型构建高效的内容创作工具,用于自动撰写营销文案、新闻稿、创意故事、剧本或社交媒体帖子,极大地提升内容生产效率。
- 代码生成与辅助该模型具备强大的代码理解和生成能力,可用于开发下一代编程辅助工具。它可以帮助程序员自动生成代码片段、调试现有代码、将代码从一种语言翻译成另一种语言,或解释复杂的代码逻辑。
QA
- 什么是“基础模型”(Base Model)?基础模型是指一个经过大规模数据预训练但尚未针对任何特定任务进行优化的模型。它就像一块可塑性很强的“原材料”,开发者可以根据自己的需求,通过微调(fine-tuning)等技术,把它塑造成特定领域的专家模型,比如聊天机器人或代码翻译器。
- 运行DeepSeek-V3.1-Base需要什么样的电脑配置?由于该模型参数量巨大(6850亿),普通个人电脑无法运行。它需要在配备多张高性能专业GPU(如图形处理单元,例如NVIDIA A100或H100)和数百GB内存的服务器上才能运行。
- 模型是免费的吗?可以用于商业产品吗?是的,该模型采用MIT许可证发布,这意味着它是完全开源的。你可以在遵守许可协议的前提下,免费地使用、修改、分发模型,甚至可以将其用于商业化的产品中。
- MoE(专家混合)架构有什么好处?MoE架构可以让模型规模变得非常大,同时保持计算效率。它将模型的知识分散到许多“专家”网络中,处理任务时,系统会智能地选择几个最相关的“专家”来激活。这样一来,虽然总参数很多,但单次计算成本却相对较低,实现了性能和效率的平衡。